什么是Job System?
Job System通过创建一个Job而不是线程来管理多线程代码,Job System在多个内核之间管理工作线程,通常一个cpu内核有一个初始线程,来避免线程上下文的切换。
Job System将多个Job放入一个工作队列去执行,工作线程从这里获取并执行他们,这个系统同样需要管理他们的依赖,并确保jobs按照合适的顺序执行。
各类Jobs介绍
什么是Job
Job是一个很小的工作单元,接收参数并操作数据,类似一个函数方法的执行行为,job可能是独立的,也可能依赖于其他job的执行结果。
什么是Job依赖性( job dependencies)
在复杂的系统里,比如游戏开发的需求,通常job并不会是独立的,一个job通常是为另一个job准备数据,Job系统支持了这个特性,如果任务a依赖于任务b,系统会保证他们有正确的执行顺序。
C#Job System如何工作
C#Job System允许用户编写与Unity的其他部分良好交互的多线程代码,并使编写正确代码的过程变得更加容易。编写多线程代码可以提供高性能的好处。这些包括显着提高帧速率。将Burst编译器与C#Job System一起使用可以提高代码生成质量(这里是指编译后生成的机器代码),这也可以大大减少移动设备上的电池消耗。
C#Job System的一个重要方面是,它与Unity内部使用的内容(Unity’s native job system)集成在一起。用户编写的代码和Unity共享工作线程。这种合作避免了创建比CPU内核更多的线程,这将导致CPU资源争用。
Job System里的安全系统
当你编写多线程代码的时候,通常会有Condition Race(条件竞争)的风险,当一个操作的输出依赖于其控制范围之外的另一个进程的执行时间时,就会出现Condition Race。
Condition Race通常不算是bug,但是是一种不确定的行为,当一个Condition Race引发一个bug,由于时间的不确定性,将会很难发现bug的真正原因,因为只能依赖Condition Race才能重现bug。在代码中debug可能导致问题莫名消失,因为断点调试和log会改变线程的时间节点,Condition Race大大增加了多线程开发的难度。
安全系统
为了让多线程开发变得简单,C# job system检测所有潜在的Condition Race,并且规避可能导致的bug。比如:当在你的主线程代码中向job发送了一个数据的引用,此时无法查证当主线程在读取数据的同时,是否有job在尝试写入,此时便产生Condition Race。
C# JobSystem通过发送每个job一份操作数据的拷贝,而不是主线程数据的引用,来解决Condition Race问题。这份拷贝隔离了数据,因此得以解决Condition Race问题。
Job System需要拷贝数据,意味着job只能访问blittable(结构体)的数据类型,这些数据类型在本地和托管代码中不需要转换。
job system可以使用memcpy来拷贝blittable的数据,并且在unity的本地堆和托管堆之间转换,他在调度job的时候,使用memcpy来将数据放入本地内存,并赋予数据的管理权限。
Blittable数据类型和非Blittable类型(附加内容)
根据微软的文档以下是Blittable
System.Byte System.SByte System.Int16 System.UInt16 System.Int32 System.UInt32 System.Int64 System.IntPtr System.UIntPtr
如果一个数组的元素是以上类型,比如整形数组 仅包含Blittable类型的值类型
以下是非Blittable类型
System.Array System.Boolean System.Char System.Class System.Object System.Mdarray System.String System.Valuetype System.Szarray
创建Job/安排Job
创造Job
要在Unity中创建Job,您需要实现IJob接口。IJob使您可以计划与其他正在运行的Job并行运行的单个Job。
注意:“Job”是Unity中所有实现该IJob接口的struct的统称。
要创建Job,您需要:
- 创建一个struct实现接口IJob。
- 添加Job使用的成员变量(blittable 类型或NativeContainer类型)。
- 在struct中创建一个名为Execute的方法,并在其中执行Job(也就是实际要做的事情)。
- 执行Job时,该Execute方法在单个内核上运行一次(应该是被分配的cpu上某个核上)。
注意:在设计Job时,请记住,它们对数据副本起作用,除非使用NativeContainer。因此,从主线程中的Job访问数据的唯一方法是写入NativeContainer。
举一个简单的Job定义的栗子
// Job将两个浮点值相加
public struct MyJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
安排Job(Scheduling Job)
要在主线程中安排Job,您必须:
- 实例化Job。
- 给Job的添加数值(其实是对Job中定义的数据赋值或者叫初始化数据)。
- 调用Schedule方法。
- 调用Schedule会将Job放入Job队列以在适当的时间执行。安排Job后,您将无法中断Job。
注意:您只能从主线程调用Schedule方法。
接上一个创建Job的例子举一个安排Job的栗子
private void StartJob()
{
//创建一个单一浮点数的原生数组来存储结果。
//为了便于说明,此示例等待任务完成
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
// 设置job数据
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
// 安排的job
JobHandle handle = jobData.Schedule();
// 等待Job完成
handle.Complete();
// nativarray的所有副本都指向相同的内存,
//你可以在nativarray的“your”副本中访问结果
float aPlusB = result[0];
// 释放结果数组分配的内存
result.Dispose();
}
JobHandle和依赖
当您调用Job的Schedule方法时,它将返回JobHandle。您可以在代码中使用JobHandle 作为其他Job的依赖。如果一个Job依赖于另一个Job的结果,则可以将第一个Job的JobHandle参数作为参数传递给第二个Job的Schedule方法,如下所示:
JobHandle firstJobHandle = firstJob.Schedule();
secondJob.Schedule(firstJobHandle);
合并依赖(Combining dependencies)
如果Job具有许多依赖关系,则可以使用JobHandle.CombineDependencies方法合并它们。CombineDependencies允许您将它们(JobHandle)作为参数。
NativeArray<JobHandle> handles = new NativeArray<JobHandle>(numJobs, Allocator.TempJob);
// 从多个调度作业中填充“handles”和“JobHandles”…
JobHandle jh = JobHandle.CombineDependencies(handles);
在主线程中等待Job
使用JobHandle就会强制让你在主线程中等待Job完成执行。为此,请在调用JobHandle的Complete方法。至此,您知道主线程可以安全地访问作业正在使用的NativeContainer。
注意:在安排(schedule)Job时,它们(Job)并不会开始执行。如果您正在主线程中等待Job,并且需要访问该Job正在使用的NativeContainer数据,则可以调用方法JobHandle.Complete。此方法从内存缓存中清除作业,并开始执行。JobHandle调用Complete将返回NativeContainer类型的数据的所有权到主线程(可以理解主线程接管了NativeContainer)。也就是说您需要调用Complete才能在再次主线程中安全的访问NativeContainer
【原文有确实有again这个词,我理解的再次的意思是:因为一开始NativeContainer是在主线程中创建的,这时Job还没有执行,当调用Complete后,主线程才能从NativeContainer获得结果,所以叫再次访问】。
通过调用Job依赖的JobHandle的Complete ,也可以将所有权返回给主线程。例如,有两个Job ,其中JobA 依赖JobB。你可以调用JobA的Complete,或者JobB的Complete。两者都可以让你在主线程安全地访问NativeContainer【JobA的结果】。
如果不需要访问数据,则需要显式刷新批处理(batch)。为此,请调用静态方法JobHandle.ScheduleBatchedJobs。请注意,调用此方法可能会对性能产生负面影响。
举个关于多个Job依赖的栗子
// Job将两个浮点值相加
public struct MyJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
// Job增加一个值
public struct AddOneJob : IJob
{
public NativeArray<float> result;
public void Execute()
{
result[0] = result[0] + 1;
}
}
private void StartJob()
{
// 创建一个单一浮点数的原生数组来存储结果。这个示例等待任务完成
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
// 为job#1设置数据
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
// Schedule job #1
JobHandle firstHandle = jobData.Schedule();
// 为job#2设置数据
AddOneJob incJobData = new AddOneJob();
incJobData.result = result;
// Schedule job #2
JobHandle secondHandle = incJobData.Schedule(firstHandle);
// 等待job#2完成
secondHandle.Complete();
// 如果NativeArrayr的所有副本都指向相同的内存,你可以在“your”copy of the NativeArrayr job中访问结果
float aPlusB = result[0];
// 释放结果数组分配的内存
result.Dispose();
}
ParallelFor类型的Job
当安排Job(scheduling jobs),只能有一个Job做一个任务。在游戏中,通常要对大量对象执行相同的操作。有一个单独的Job类型称IJobParallelFor来处理此问题。
注意:“ ParallelFor”类型 Job是Unity中所有实现该IJobParallelFor接口的struct的统称。
ParallelFor类型的Job使用NativeArray作为其数据源。ParallelFor类型Job跨多核(cpu的核)运行。每个核有一个Job,每个Job处理一部分工作量。IJobParallelFor行为类似于IJob,但它不是单个Execute方法,而是Execute对数据源中的每个项目调用一次该方法。该Execute方法中有一个整数参数。改参数作为索引用于访问Job实现中的数据源中的单个元素并对其进行操作
struct IncrementByDeltaTimeJob: IJobParallelFor
{
public NativeArray<float> values;
public float deltaTime;
public void Execute (int index)
{
float temp = values[index];
temp += deltaTime;
values[index] = temp;
}
}
安排ParallelFor类型的Job
安排ParallelFor时,必须指定NativeArray要拆分的数据源的长度。如果NativeArray中有多个,那么Unity C#Job System无法知道您要将哪个用作数据源。并且该长度还告诉Job System需要多少Execute种方法。
Job System 内部对于ParallelFor 类型的Job调度更加复杂。当安排ParallelFor类型的Job时,C#Job System工作分为几批以在内核之间分配。每个批次都包含Execute方法的子集。然后,C#Job System在每个CPU内核的Unity本地作业系统中最多安排一个作业,并将该本地作业传递一些批次以完成。
【下面的示意图展示是有8个ParallelFor 类型的Job,在C# Job System中被分成了4个批次,每个批次中2个Job。在Job队列中这4个批次又被合并成2个本地Job,这两个本地Job在本地Job System中被分配到两个线程,分别在两个cpu内核在执行。通过下图也再次说明了Job并不是线程】
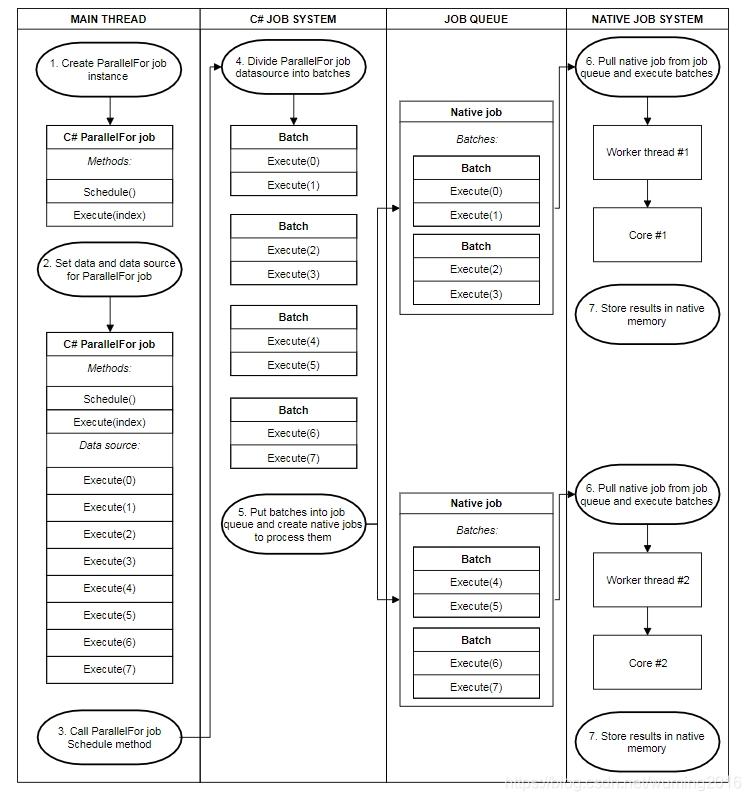
当本机作业比其他作业先完成其批次时,它将从其他本机作业中窃取剩余的批次。它一次只窃取本机作业剩余批次的一半,以确保缓存位置。
要优化流程,您需要指定批次计数。批计数控制您获得多少个作业,以及线程之间的工作重新分配的粒度。批处理计数较低(例如1)可以使线程之间的工作分配更加均匀。它的确有一些开销,因此有时最好增加批数。从1开始并增加批数直到出现微不足道的性能提升是一种有效的策略。
// Job将两个浮点值相加
public struct MyParallelJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<float> a;
[ReadOnly]
public NativeArray<float> b;
public NativeArray<float> result;
public void Execute(int i)
{
result[i] = a[i] + b[i];
}
}
void StartJob()
{
NativeArray<float> a = new NativeArray<float>(2, Allocator.TempJob);
NativeArray<float> b = new NativeArray<float>(2, Allocator.TempJob);
NativeArray<float> result = new NativeArray<float>(2, Allocator.TempJob);
a[0] = 1.1f;
b[0] = 2.2f;
a[1] = 3.3f;
b[1] = 4.4f;
MyParallelJob jobData = new MyParallelJob();
jobData.a = a;
jobData.b = b;
jobData.result = result;
//调度job时,对结果数组中的每个索引执行一次,每个处理批中只执行一个项目
JobHandle handle = jobData.Schedule(result.Length, 1);
//等待job完成
handle.Complete();
//释放数组分配的内存
a.Dispose();
b.Dispose();
result.Dispose();
}
ParallelForTransform类型的Job
一个ParallelForTransform类型的Job是另一种类型的ParallelFor类型的Job ,专为在Transforms上运行而设计。
注意:ParallelForTransform类型的Job是Unity中所有实现IJobParallelForTransform接口的Job的统称。
C#Job System提示和故障排除
使用Unity C#Job System时,请确保遵守以下规定:
不要从Job访问静态数据
从Job中访问静态数据会绕过所有安全系统。如果您访问了错误的数据,则可能会导致Unity崩溃,并且经常发生意外情况。例如,访问MonoBehaviour可能会导致域重新加载时崩溃。
注意:由于存在这种风险,未来的Unity版本将阻止使用静态分析(static analysis)从Job访问全局变量。如果您确实Job中访了的静态数据,那么在将来的Unity版本中会中断【也就是断了这念想,现在不crush将来的版本也会不能用】。
填充已经安排批次Flush scheduled batches
当您希望Job开始执行时,可以使用JobHandle.ScheduleBatchedJobs刷新计划的批处理。请注意,调用此方法可能反而会影响性能。不这样做,那么批次就会被延迟调度,直到主线程等待结果为止。在所有其他情况下,请使用JobHandle.Complete。
注意:在ECS中,该批次将为您隐式填充,因此JobHandle.ScheduleBatchedJobs无需调用。
正确的更新NativeContainer的内容
由于缺少引用返回,因此无法直接更改NativeContainer的内容。例如:
nativeArray[0]++;
或者
var temp = nativeArray[0];
temp++;
以上两种写法都不能更新nativeArray。您必须将数据从索引复制到本地临时变量(副本),修改该临时变量,然后将其保存回,如下所示:
MyStruct temp = myNativeArray[i];
temp.memberVariable = 0;
myNativeArray[i] = temp;
调用JobHandle.Complete重新获得所有权
跟踪数据所有权需要先完成依赖关系,然后主线程才能再次使用它们。仅用JobHandle.IsCompleted检查是不够的。您必须调用JobHandle.Complete以让主线程重新获得NativeContainer的所有权。调用Complete还会清除安全系统中的状态。不这样做会导致内存泄漏。此过程也使用于:每帧依赖于前一帧作业的帧上计划新作业。
在主线程中使用Schedule和Complete
您只能从主线程调用Schedule和Complete。如果一个作业依赖于另一个Job,请使用它JobHandle来管理依赖性,而不要尝试在Job中schedule作业。
在正确的时间调用Schedule and Complete
当需要的数据准备好了后就可以调用Schedule,而Complete直到需要结果时再调用它。最佳实践是安排一个无需与正在运行的其他作业竞争的Job,不需要等待的Job。例如,如果您在一个帧的结束到下一帧的开始之间有一个不运行任何Job的时间段,并且可以接受一帧的延迟,则可以将Job调度到一帧的结尾并使用其结果在以下一帧中。或者,如果您的游戏使该转换期与其他Job饱和,并且框架中其他地方存在未充分利用的大时期,那么将您的Job安排在那里的效率更高。
将NativeContainer类型标记为只读
请记住,默认情况下,Job拥有NativeContainer类型的读写权限。[ReadOnly]适当时使用属性以提高性能。
检查数据依赖性
在Unity Profiler窗口中,主线程上的标记“ WaitForJobGroup”指示Unity正在等待工作线程上的Job完成。此标记可能意味着您在应该解决数据依赖性。查找JobHandle.Complete以跟踪您在哪些位置具有数据依赖关系,这些数据依赖关系迫使主线程等待。
调试(Debugging)Job
Job有Run函数可以用来代替该Schedule,该方法能立即在主线程上执行Job。您可以将其用于调试目的。
不要在Job中分配托管内存
在Job中分配托管内存的速度非常慢,并且该Job无法利用Unity Burst编译器来提高性能。Burst是一种新的基于LLVM的后端编译器技术,使您的工作更轻松。它利用C#Job System并利用平台的特定功能来生成高度优化的机器代码。
什么是NativeContainer?
NativeContainer是一个对Unity本地内存进行相对安全的封装并且接受管理的值类型。在使用Unity JobSystem时,NativeContainer允许job和主线程访问共享内存,而不是通过内存拷贝。
有哪些NativeContainer可以用?
Unity提供了一个NativeContainer叫做NativeArray,你可以通过NativeSlice从特定位置开始操作固定长度操作NativeArray的数据子集。
注意:Unity ECS系统拓展了Unity.Collection命名空间下的NativeContainer类型:
- NativeList - 可变长度的NativeArray
- NativeHashMap - 键值对
- NativeMultiHashMap - 一键多值的哈希表
- NativeQueue - 先入先出列表
NativeContainer和Safety System之间的关系
Safety System(安全系统)是在所有NativeContainer类型中内置的,它追踪了是谁在读写NativeContainer。
注意:所有NativeContainer的安全类型检查(如:越界检查、释放检查、依赖检查),都只在Editor和PlayMode下有效。
SF中的部分概念DisposeSentinel和AtomicSafetyHandle
-
DisposeSentinel可能会在内存泄露后很久,才会触发并给出内存泄漏的错误日志
-
在代码中使用AtomicSafetyHandle移交NativeContainer的权限, 比如:
如果两个Job同时写入NativeArray,SF在你调度Job的时候就会抛出清晰的异常日志来告诉你怎么去解决这个问题。因此你可以根据Job的依赖关系来调度,在第一个job完成nativeContainer的写入之后,第二个Job可以安全的读写同一个NativeCondition,当然主线程读写的时候一样需要严格限制。SF也允许多个并行Job的读取同一个数据。
一个Job在默认情况下拥有NativeContainer的读写权限,这有可能会拖累性能表现,C# 的SF不允许一个Job在另一个Job写入数据的时候拥有写入权限,如果不需要写入权限,可以在NativeContainer上添加**[ReadOnly]**标签,比如:
[ReadOnly]
public NativeArray<int> input;
这样其他Job就可以在当前job执行的时候,获得NativeArray的只读权限
注意:在访问静态数据的时候是不会有SF的安全保护的,静态数据绕过了所有的SF,因此可能导致Unity崩溃。
NativeContainer 的分配
- Allocator.Temp 分配速度最快,试用于生命周期在一帧以内的job,你需要在方法结束之前调用Dispose方法
- Allocator.TempJob 分配速度比Temp慢,但是比Persistent快,适用于生命周期在四帧以内的Job,是线程安全的,如果你没有手动调用Dispose方法,会在四帧之后输出一条警告日志,大部分小Job会采用这种类型
- Allocator.Persistent 分配速递最慢,但是可以存在任意长的时间,必要的话可以贯穿整个应用的生命周期。本质上是malloc的直接封装,其他更长的Job可以用这种类型,当然性能有压力的时候,还是不要使用
Job优化流程
- 使用Job运行耗时计算
- 将物体的Trans from平铺
- 优化Job依赖
- 开启Burst